Animatable Nerf Preparation
The Problem
I want to decouple NeRF rendering from deformation to create a framework for animatable NeRFs. This would allow training a model on arbitrary volume deformations, rather than relying on input videos or physics simulations, to view the NeRF as if it were deformed. Implementation requires addressing several factors within the render pipeline.
Rendering a NeRF
The main step to a NeRF render is raymarching. Cast rays from the camera into a field, sample the NeRF model along these rays, and composite the samples into a final image. And if I want to deform this NeRF, I can represent it with two separate volumes. A "deformed" volume, where the camera resides, and a "canonical" volume, where the static NeRF resides. The camera casts straight rays through the deformed volume, since the resulting deformed NeRF is what I want to view for a given instance of the animation. Then in order to get the density and color of a NeRF at a certain ray sample in the deformed volume, I need a model/method to correlate these samples back to a point in the canonical volume. I will be referring this correlation back to the canonical volume as the "inverse deformation". In essence, I map straight rays from the deformed volume to learned, curved rays within the canonical volume. These curved rays sample the static NeRF, relaying its data to the correlated camera sample in order to render a deformed NeRF.
This inverse deformation problem is a fundamentally simple problem to understand, however it gets substantially more complex when real-time performance is a factor. Some key features for real-time performance of static NeRFs are found in InstantNGP's NeRF implementation: a faster model (compared to previous NeRF implementations), and a volumetric "mask" via a binary voxel-based occupancy grid (determines if the NeRF occupies a particular region in space). The first feature is straightforward to translate to a non-static NeRF, but the occupancy grid is where things could get out of hand.
Where is the NeRF?
Obviously, an occupancy grid works fine if the NeRF is static, but it will fail to function once the NeRF deforms. As the NeRF is no longer where the occupancy grid expects it to be. The inverse deformation model could be used at every sample until you reach the static occupancy grid in the canonical volume, but this largely ignores the speed-up of using the occupancy grid as a sampling mask. So why not just create another occupancy grid for the deformed volume? Caching occupancies for all deformed frames can definitely work for a singular deformation or even a short time-tracked animation. All I would need to do is define a frame index I want to render, raymarch with that frame's deformed occupancy grid, and only sample the inverse deformation model and the NeRF when rays pass through this deformed occupancy grid. However, what about expanding past fixed framecount animations? Such as animating based on a combination of various parameters. Anywhere from pose animation with a skeleton to face animation via blendshapes to secondary effects such as muscle or hair simulation based on the more strict parameters. A 128^3 binary occupancy grid may only be 0.2 megabytes, but pre calculating and storing millions of these to handle every scenario would be a poor use of computation power and memory.
So the problem becomes: how can this be avoided? One strategy is to use a simple, direct point-to-point model for the inverse deformation correlation, while a separate, complex model handles predicting the required occupancy grid in real-time. It is an interesting approach that I would like to test in the future, but the implementation I took for this project takes a different approach.
Implementation of the Inverse Deformation Model
Theres two aspects I want to preserve in a real-time focused implementation of an animatable NeRF: keep an occupancy grid for sample masking, and prevent multiple inverse deformation model samples per ray before the occupancy grid is reached. Meaning, I wanted a way to get the resulting full deformed ray with one pass of the inverse deformation model, allowing for much quicker sampling before the occupancy grid is reached. No going between the CPU and GPU after each inverse deformation model sample to see which points should start sampling from the NeRF model and which are still in empty space. Knowing that the ray sampling in the canonical space is a warped/curved version of the ray in the deformed volume, I figured replicating that curve with parametric curves is the way to go.
Model Progression
Before Hopping directly into a parametric curve implementation, I worked my way through more complex/abstract models. In order of testing, they are:
1. Direct Point Correlation Model
- For any point (x, y) in the deformed volume, output the point (x’, y’) that correlates to the correct point in the canonical volume
2. Point Offsets Model
- For any point (x, y) in the deformed volume, output the offsets (i, j),that makes (x + i, y + j) correlate to the correct point in the canonical volume
3. Ray Origin Model
- For a given origin point of a camera ray (x, y) and t for distance along the ray, output the offsets (i, j), that makes (x + i, y + j) correlate to the correct point in the canonical volume
4. Batch Ray Origin Model
- For a given origin point of a camera ray (x, y), output an array of offsets along the entire ray < i, j >, that makes each (x + i, y + j) at a given t distance along the ray correlate to the correct points in the canonical volume
5. Akima Spline Model
- For a given origin point of a camera ray (x, y) and ray angle , output a set of akima spline knot parameters < i, j, t >to define parameterized offset splines for each axis: < i, t > for the x axis, and < j, t > for the y axis. The predicted t values are shared between the x axis spline and y axis spline. Use the t value for the current camera ray sample to perform the standard functions for an Akima spline and combine with the camera sample (x, y) to get the corralated point in the canonical volume
6. Entry/Exit Akima Spline Model
- For a given entry point into the deformed volume’s bounding box (x_entry, y_entry) and a given exit point of the deformed volume’s bounding box (x_exit, y_exit), output the same splines as the Akima Spline Model
Training Environment
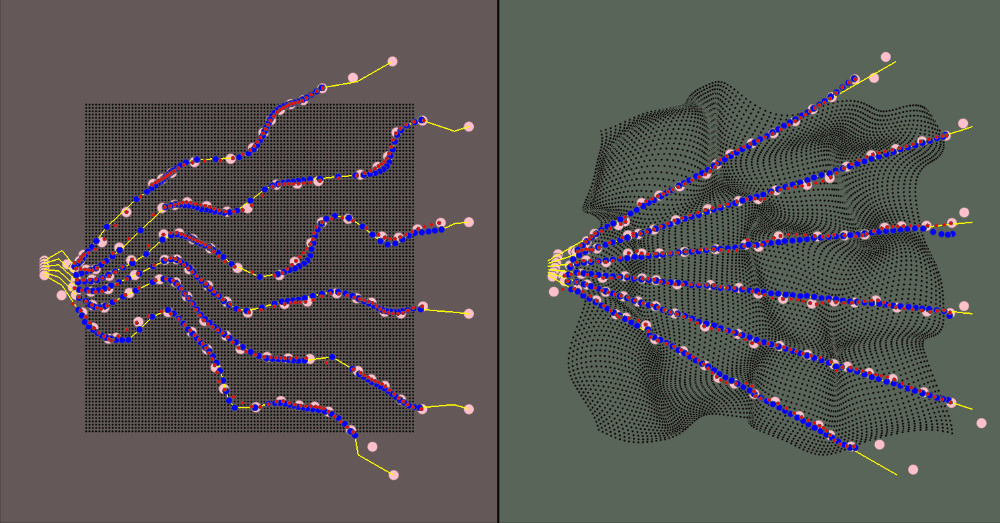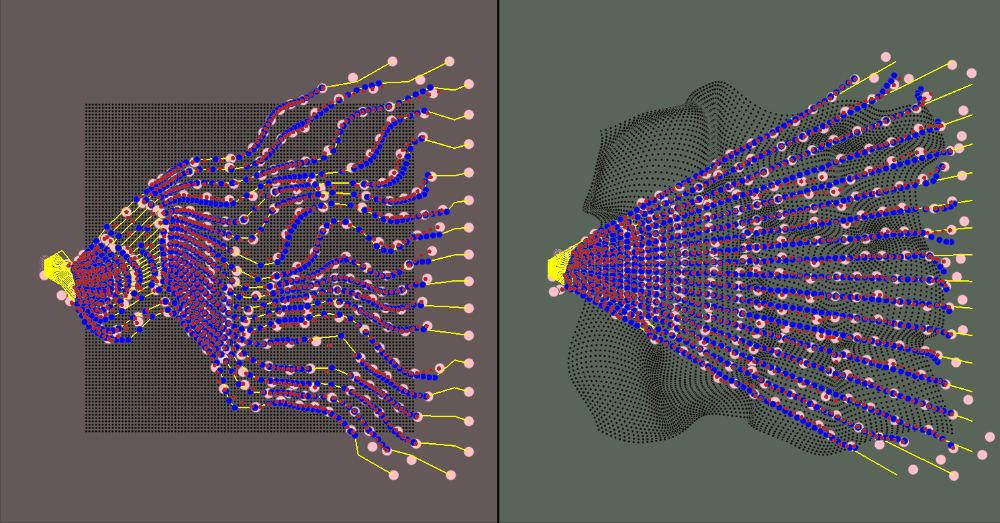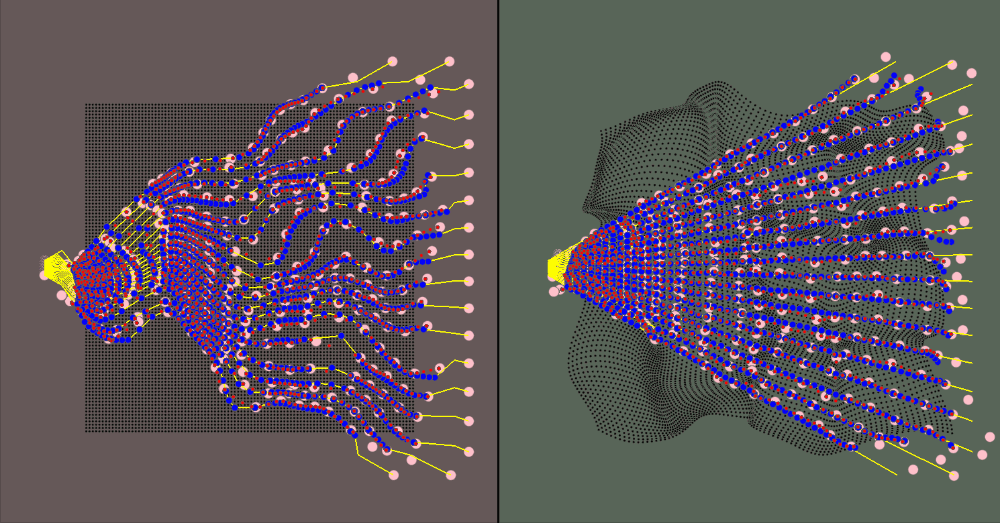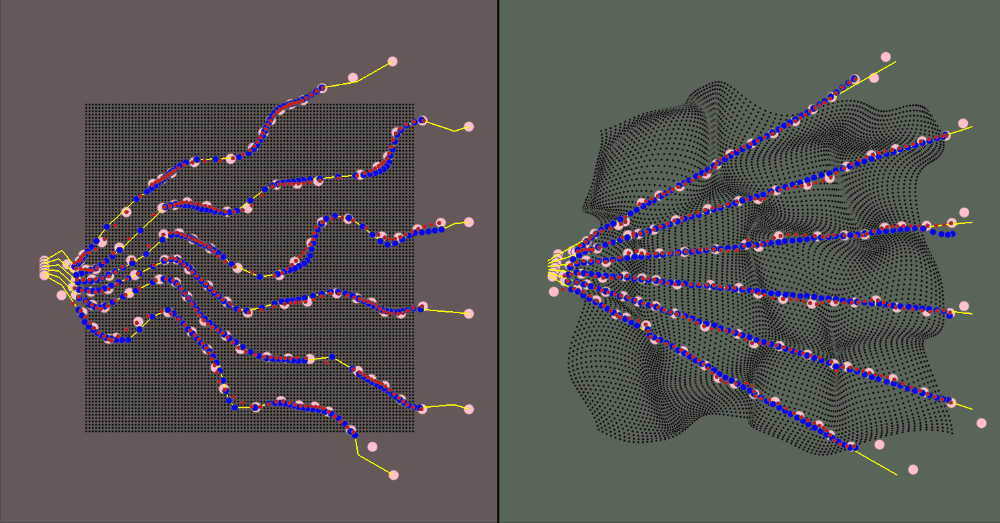
The majority of the values (deformation parameters, camera position/rotation/resolution) are configurable. The gif above shows how the ray count can be changed on the fly. In fact, since the inverse deformation model only considers one ray in its model size for input/output, you can change the "resolution" without retraining the model
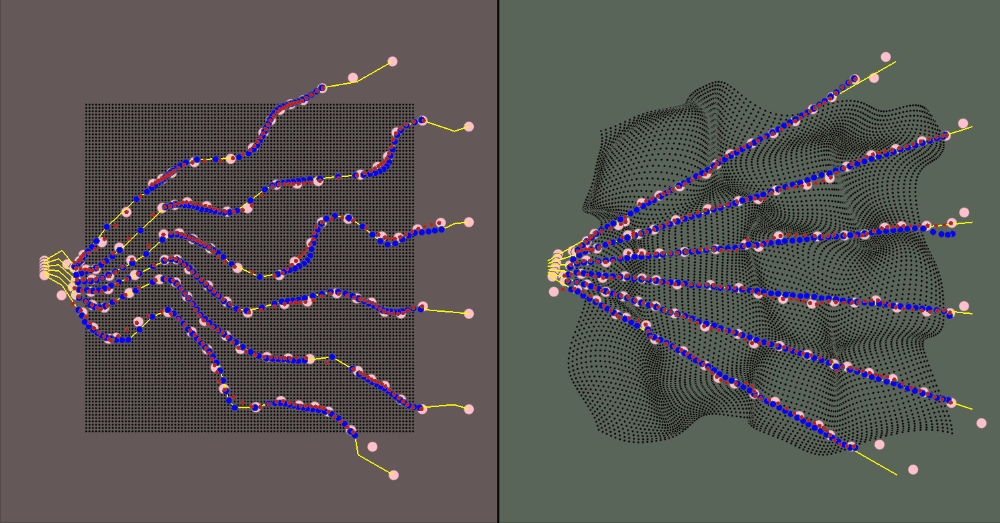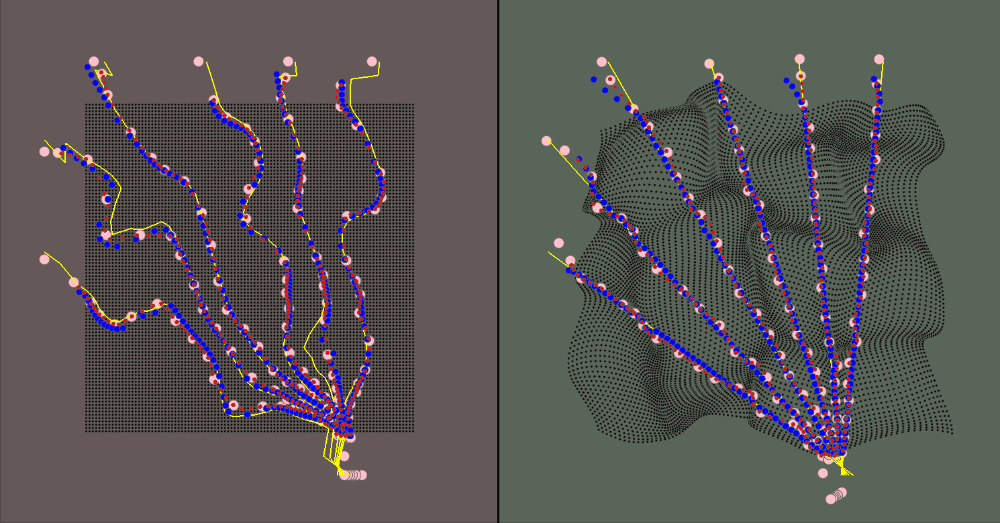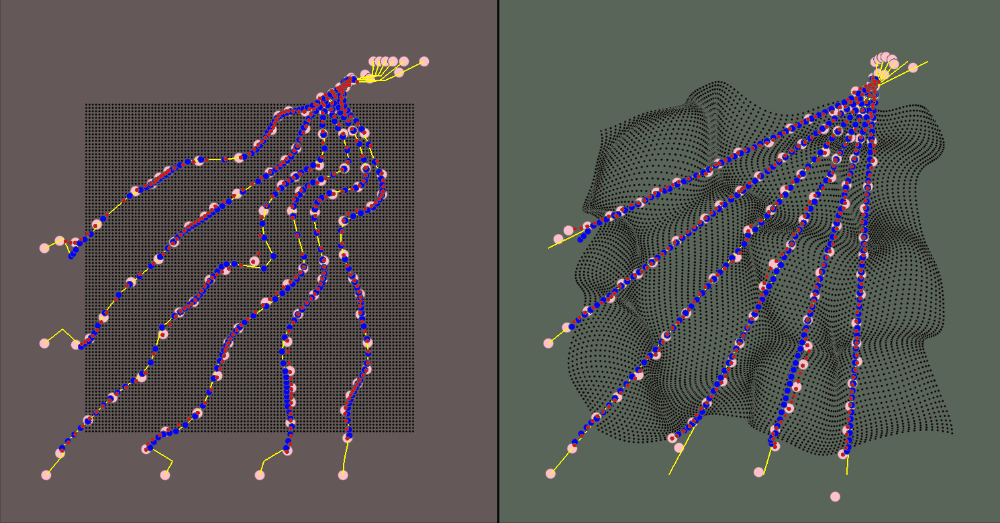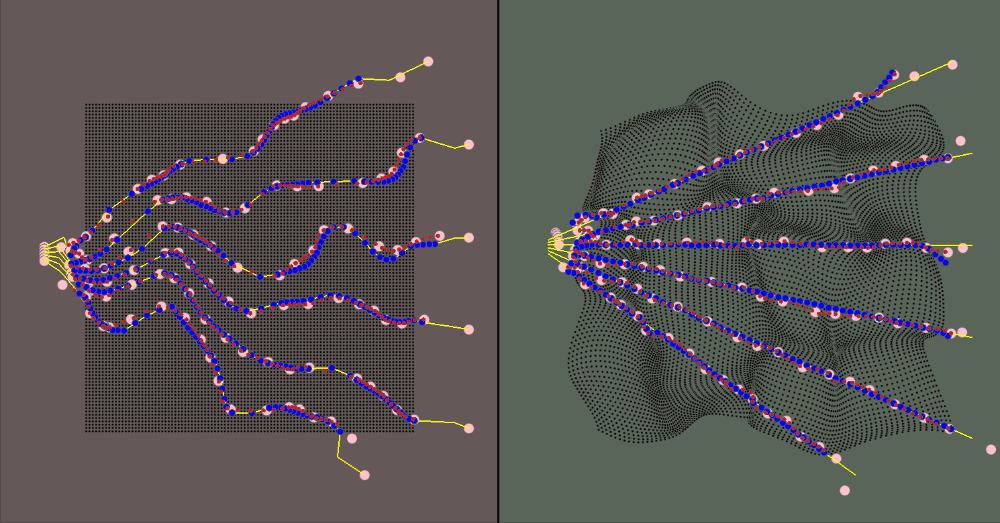
The visualization for the environment is:
- The red area is the canonical space
- The green area is the deformed space
- The black dots represent the canonical object when in the canonical space and the correlated deformed points in the deformed space
- The yellow rays represent the camera rays
- The pink dots are the spline knots
- The red dots are the predicted values (calculated using the spline knots)
- The blue dots are the ground truth samples
The training data is a jittered sample of camera positions along an orbiting path
Results
The model does a decent job tracking the deformation throughout a camera orbit, but there are some noticeable points of improvement. Of course, overall accuracy could improve, but also there is a "wobble" between very small camera movements. I have tried various loss calculation improvements, such as taking into account ray smoothness, ray neighbor consistency, and ray reprojection straightness. They have not resulted in significant improvements for solely the orbital camera path, but more testing needs to be done to find the optimal weightings for these loss functions. Also, there was not a significant difference between using the camera ray origins versus using the entry/exit points, however I believe this is mostly due to the training data being limited to a mostly-fixed distance orbit around the object. Entry/exit should help the model generalize with free camera movement.